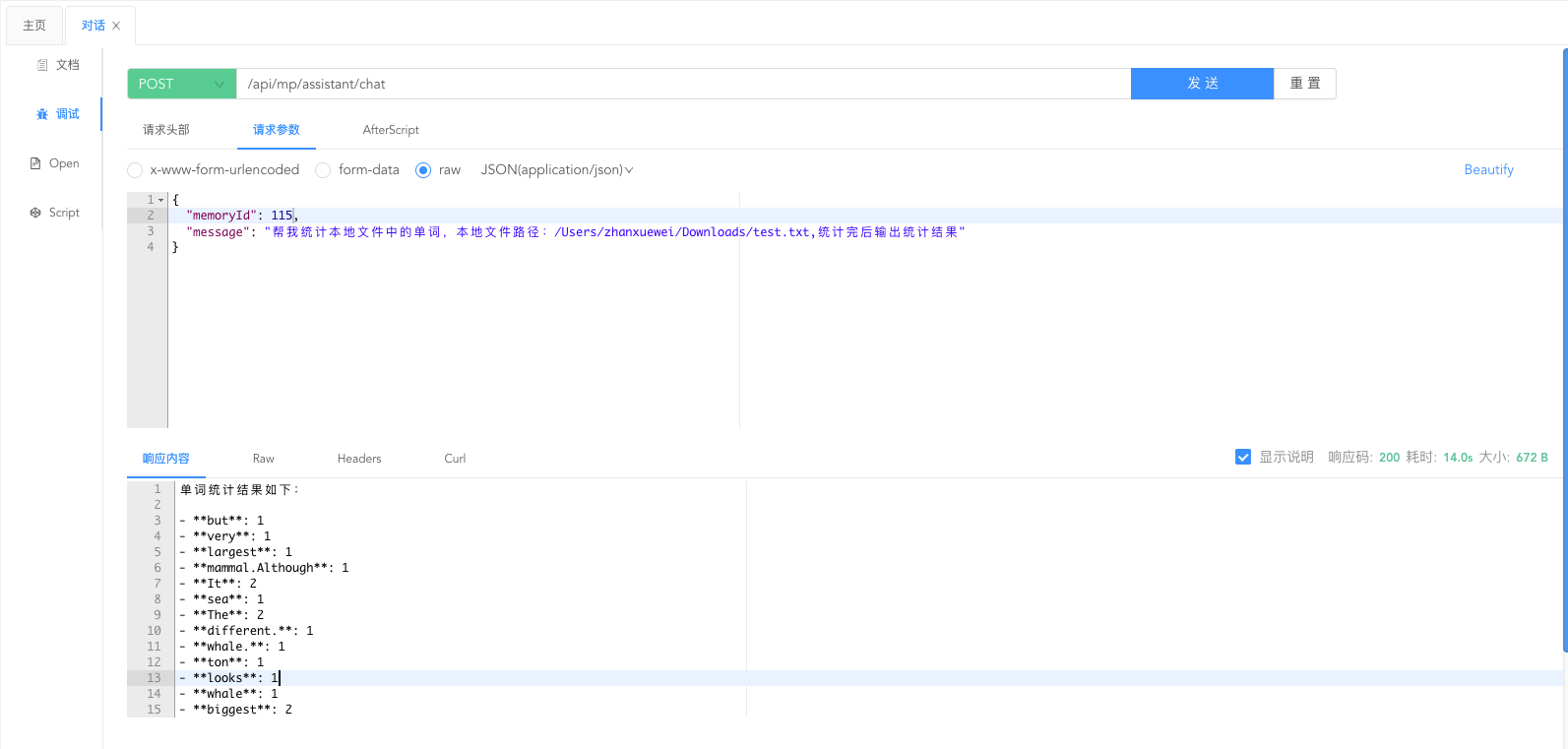
今天要实现的功能是:通过langchian4j的函数调用,实现上传本地文件到HDFS文件系统,同时执行Mapreduce程序,完成WordCount功能,最后读取单词统计结果。
扩展:这里还可以调用咱们的sql的Tool,可以将结果存入数据库等操作~~
一、搭建大数据环境
搭建过程就不多说了,步骤比较多,我记得之前的文章有介绍,有疑问的伙伴可以相互交流~~
这里我使用的是hadoop3.0,使用的三台机器搭建的HA高可用集群。
二、添加依赖
<!-- Hadoop客户端 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.6</version>
</dependency>
<!-- 配置文件处理器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>在上一个项目的基础上,这里又添加了hadoop客户端的依赖,主要是为了和hdfs文件系统交互。
三、添加了自定义的配置文件:
hadoop:
fs-defaultFS: hdfs://node2:8020
yarn-resourcemanager: node1:8032
mapreduce-framework: yarn
username: root这里是hadoop集群的配置,本地测试就简单弄下。
四、配置hadoop的配置类:
package com.zhan.ailangchian4j.hadoop.config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.apache.hadoop.conf.Configuration;
/**
* @author zhanxuewei
*/
@org.springframework.context.annotation.Configuration
public class MyHadoopConfig {
@Value("${hadoop.fs-defaultFS}")
private String fsDefaultFS;
@Bean
public Configuration hadoopConfig() {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", fsDefaultFS);
conf.setBoolean("dfs.client.use.datanode.hostname", true);
return conf;
}
}五、编写Tools
1.这里我分了两个,一个是使用mapreduce执行wordcount程序的Tools:
package com.zhan.ailangchian4j.hadoop.tools;
import com.zhan.ailangchian4j.hadoop.utils.DateUtil;
import com.zhan.ailangchian4j.hadoop.utils.WordCountParser;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.FileInputStream;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
/**
* @author zhanxuewei
*/
@Slf4j
@Component
public class HdfsTools {
@Autowired
private Configuration hadoopConf;
@Tool(name = "查看wordCount程序统计结果文件中的内容", value = "执行Hadoop MapReduce单词统计任务后,会在目标路径下生成统计结果文件,需要一个参数:执行完wordCount后生成的hdfs结果文件路径")
public Map<String, Integer> wordCount(@P(value = "wordCount单词统计结果文件路径,例如:/output/part-r-00000") String outputPath) {
try {
FileSystem fs = FileSystem.get(hadoopConf);
Path dirPath = new Path(outputPath);
// 递归列出所有文件
RemoteIterator<LocatedFileStatus> fileIterator = fs.listFiles(dirPath, true);
byte[] buffer = new byte[4096];
StringBuilder content = new StringBuilder();
while (fileIterator.hasNext()) {
LocatedFileStatus fileStatus = fileIterator.next();
System.out.println("文件路径: " + fileStatus.getPath());
System.out.println("文件大小: " + fileStatus.getLen() + " bytes");
System.out.println("块大小: " + fileStatus.getBlockSize() + " bytes");
System.out.println("副本数: " + fileStatus.getReplication());
System.out.println("修改时间: " + fileStatus.getModificationTime());
System.out.println("----------------------------------");
if (fileStatus.getPath().getName().contains("part-r-")) {
FSDataInputStream in = fs.open(new Path(outputPath));
int bytesRead;
while ((bytesRead = in.read(buffer)) > 0) {
content.append(new String(buffer, 0, bytesRead));
}
}
}
return WordCountParser.parseResult(content.toString());
} catch (Exception e) {
log.error("查看wordCount程序统计结果文件中的内容失败", e);
return new HashMap<>();
}
}
@Tool(name = "上传本地文件到hdfs文件系统", value = "上传本地文件到hdfs文件系统,返回的是文件上传到hdfs后到hdfs文件的目录,需要一个参数:本地文件路径")
public String uploadLocalFileToHdfs(@P(value = "本地文件路径,例如:/output/test.txt") String localFilePath) {
String remotePath = "/data/wordcount/input/" + DateUtil.createPath();
try {
FileSystem fs = FileSystem.get(hadoopConf);
try (FSDataOutputStream output = fs.create(new Path(remotePath))) {
File file = new File(localFilePath);
IOUtils.copyBytes(new FileInputStream(file), output, 4096);
}
return remotePath;
} catch (Exception e) {
return "上传失败: " + e.getMessage();
}
}
@Tool(name = "上传文件到hdfs文件系统", value = "上传文件到hdfs文件系统,接收用户上产的一个文件,返回的是文件上传到hdfs后到hdfs文件的目录,需要一个参数:用户上传的文件对象")
public String updateFileToHdfs(@P(value = "本地文件路径,例如:/output/test.txt") MultipartFile file) {
String remotePath = "/data/wordcount/input/" + DateUtil.createPath();
try {
FileSystem fs = FileSystem.get(hadoopConf);
try (FSDataOutputStream output = fs.create(new Path(remotePath))) {
IOUtils.copyBytes(file.getInputStream(), output, 4096);
}
return remotePath;
} catch (Exception e) {
return "上传失败: " + e.getMessage();
}
}
}1.1 Mapper类:
package com.zhan.ailangchian4j.hadoop.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author zhanxuewei
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
//Mapper输出kv键值对 <单词,1>
private Text keyOut = new Text();
private final static LongWritable valueOut = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将读取的一行内容根据分隔符进行切割
String[] words = value.toString().split("\\s+");
//遍历单词数组
for (String word : words) {
keyOut.set(word);
//输出单词,并标记1
context.write(new Text(word), valueOut);
}
}
}
1.2 Reduce类:
package com.zhan.ailangchian4j.hadoop.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author zhanxuewei
*/
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable result = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//统计变量
long count = 0;
//遍历一组数据,取出该组所有的value
for (LongWritable value : values) {
//所有的value累加 就是该单词的总次数
count += value.get();
}
result.set(count);
//输出最终结果<单词,总次数>
context.write(key, result);
}
}
1.4 Driver类:
package com.zhan.ailangchian4j.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
/**
* @author zhanxuewei
*/
@Component
public class WordCountDriver_v1 {
@Autowired
private Configuration hadoopConf;
public void runWordCount(String inputPath, String outputPath) throws Exception {
//配置文件对象
// Configuration conf = new Configuration();
// conf.set("mapreduce.framework.name", "yarn");
// 创建作业实例
Job job = Job.getInstance(hadoopConf, WordCountDriver_v1.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(WordCountDriver_v1.class);
// 设置作业mapper reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(inputPath));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(outputPath));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(hadoopConf);
if (fs.exists(new Path(outputPath))) {
fs.delete(new Path(outputPath), true);
}
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag ? 0 : 1);
}
}
2.第二是获取wordcount统计结果的Tools:
package com.zhan.ailangchian4j.hadoop.tools;
import com.zhan.ailangchian4j.hadoop.utils.WordCountParser;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
/**
* @author zhanxuewei
*/
@Slf4j
@Component
public class HdfsTools {
@Autowired
private Configuration hadoopConf;
@Tool(name = "查看wordCount程序统计结果文件中的内容", value = "执行Hadoop MapReduce单词统计任务后,会在目标路径下生成统计结果文件,需要一个参数:执行完wordCount后生成的hdfs结果文件路径")
public Map<String, Integer> wordCount(@P(value = "wordCount单词统计结果文件路径,例如:/output/part-r-00000") String outputPath) {
try {
FileSystem fs = FileSystem.get(hadoopConf);
FSDataInputStream in = fs.open(new Path(outputPath + "/part-r-00000"));
byte[] buffer = new byte[4096];
StringBuilder content = new StringBuilder();
int bytesRead;
while ((bytesRead = in.read(buffer)) > 0) {
content.append(new String(buffer, 0, bytesRead));
}
return WordCountParser.parseResult(content.toString());
} catch (Exception e) {
log.error("查看wordCount程序统计结果文件中的内容失败", e);
return new HashMap<>();
}
}
}3.顺便贴上自然语言转sql的Tools:
package com.zhan.ailangchian4j.hadoop.tools;
import dev.langchain4j.agent.tool.*;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Component;
import java.util.*;
/**
* @author zhanxuewei
*/
@Component
public class MySQLQueryTool {
private final JdbcTemplate jdbcTemplate;
public MySQLQueryTool(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Tool(name = "queryWithConditions",
value = "根据条件查询MySQL数据")
public List<Map<String, Object>> queryData(
@P("表名") String table,
@P("查询字段,逗号分隔") String fields,
@P("条件键值对,格式: key1=value1,key2=value2") String conditions) {
String sql = buildQuerySQL(table, fields, parseConditions(conditions));
return jdbcTemplate.queryForList(sql);
}
private Map<String, String> parseConditions(String conditionStr) {
Map<String, String> conditions = new HashMap<>();
for (String pair : conditionStr.split(",")) {
String[] kv = pair.split("=");
if (kv.length == 2) {
conditions.put(kv[0].trim(), kv[1].trim());
}
}
return conditions;
}
private String buildQuerySQL(String table, String fields,
Map<String, String> conditions) {
StringBuilder sql = new StringBuilder("SELECT ")
.append(fields).append(" FROM ").append(table);
if (!conditions.isEmpty()) {
sql.append(" WHERE ");
conditions.forEach((k, v) ->
sql.append(k).append("='").append(v).append("' AND "));
sql.setLength(sql.length() - 5); // 移除末尾的AND
}
return sql.toString();
}
}六、最后就是AIService代码:
package com.zhan.ailangchian4j.hadoop.assistant;
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.spring.AiService;
import dev.langchain4j.service.spring.AiServiceWiringMode;
import reactor.core.publisher.Flux;
/**
* @author zhanxuewei
*/
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,
// chatModel = "qwenChatModel",
streamingChatModel = "qwenStreamingChatModel",
chatMemoryProvider = "mapreduceChatMemoryProvider",
// tools = "mapreduceTools",
tools = {"calculatorTools", "mapreduceTools", "mySQLQueryTool","hdfsTools"},
contentRetriever = "mapreduceContentRetriever"
//contentRetriever = "contentRetrieverPincone"
)
public interface MapreduceAgent {
@SystemMessage(fromResource = "mp-prompt.txt")
Flux<String> chat(@MemoryId Long memoryId, @UserMessage String userMessage);
}
这里需要注意,一个AIService是如何配置多个Tools的。
七、补充一下我的系统消息提示词:
你的名字是“学伟智能助手”,你是一个多功能助手,可以进行数学计算和MySQL数据查询。
你是大数据领域的专家,也是精通sql的大佬。
你态度友好、礼貌且言辞简洁。
1、请仅在用户发起第一次会话时,和用户打个招呼,并介绍你是谁。
2、作为一个多功能助手:
请基于大数据领域、数据库相关的知识,针对用户提出的相关问题,提供详细、准确且实用的建议。
4、你必须遵守的规则如下:
在单词统计之前,你必须确保自己知读取的HDFS文件目录(必选)、统计结果存放的HDFS目录(必选)。
在sql执行前,你必须确保自己知道读取的表名称、字段名称、过滤字段和过滤字段的值列表。
当被问到其他领域的咨询时,要表示歉意并说明你无法在这方面提供帮助。
5、请在回答的结果中适当包含一些轻松可爱的图标和表情。
6、今天是 {{current_date}}。八、结果展示:
1.我上传的测试文件:

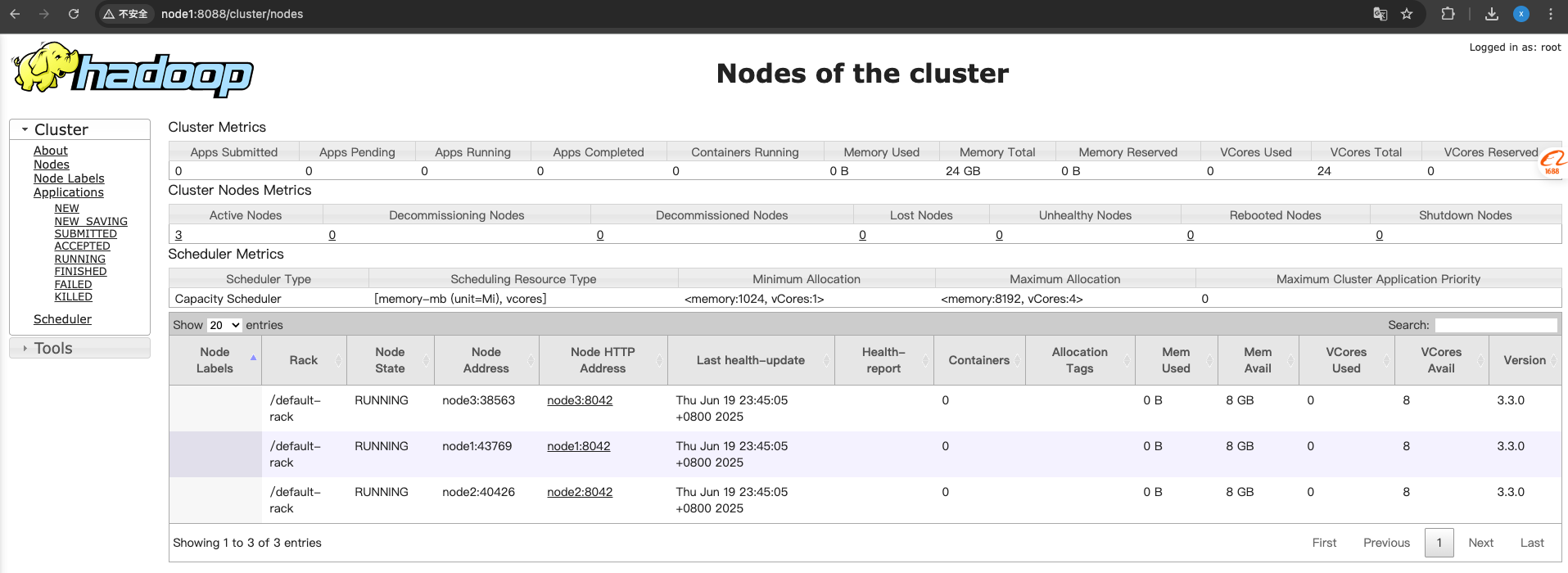
2.文件位于HDFS位置:
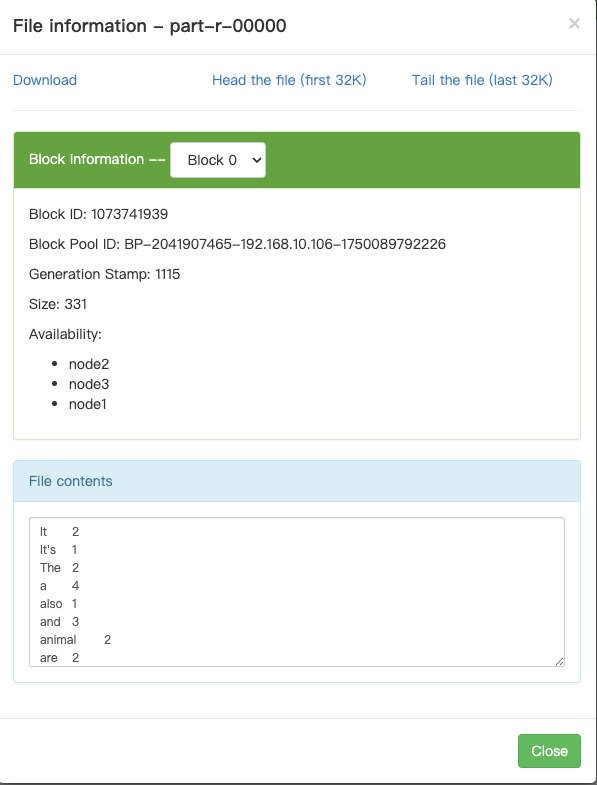
3.接口测试结果: